MMLU: Better Benchmarking for LLM Language Understanding
Brad Nikkel

For some time, many of the same language models that could plow through natural language processing (NLP) benchmarks were lousy at natural language understanding (NLU). To address this gap, Wang et al. introduced an NLU benchmark, General Language Understanding Evaluation (GLUE), in 2018. Within around a year, though, LLMs achieved human-level performance on the GLUE, motivating Wang et al. to craft the more challenging SuperGLUE benchmark in 2019. LLMs, however, made easy work of SuperGlue, again within about a year’s time.
In our journey through Hugging Face’s Open LLM Leaderboard, we’ve examined LLM benchmarks for question-answering (ARC) and common-sense reasoning (HellaSwag), both important attributes LLMs should have. We’d also like LLMs that truly get language, though. The benchmark we’ll learn about next—Massive Multitask Language Understanding (MMLU)—attempts to measure this.
Benchmarking Language Understanding: MMLU
For some time, many of the same language models that could plow through natural language processing (NLP) benchmarks were lousy at natural language understanding (NLU). To address this gap, Wang et al. introduced an NLU benchmark, General Language Understanding Evaluation (GLUE), in 2018. Within around a year, LLMs achieved human-level performance on the GLUE benchmark, motivating Wang et al. to craft the more challenging SuperGLUE benchmark in 2019. LLMs, however, made easy work of SuperGlue, again within about a year’s time.
Hoping to create a more challenging NLU benchmark (or at least a benchmark that LLMs wouldn’t breeze over within a mere year), Hendrycks et al. developed Measuring Massive Multitask Language Understanding (MMLU), a broad benchmark of how well an LLM understands language and can solve problems with the knowledge it encountered during training. Since language understanding is a far different task than the language generation tests we’ve already discussed (ARC generates answers and HellaSwag generates context completions), this benchmark makes the Hugging Faces Open LLM Leaderboard more comprehensive.
To craft a tough NLU benchmark, Hendrycks et al. drew from various subjects—including humanities, social and hard sciences, and other challenging subjects—at varying depths, from elementary to advanced professional levels. Testing specialized knowledge was unique to MMLU because most existing NLU benchmarks (when MMLU was released) focused on elementary knowledge. To get an idea of specialized knowledge questions, here are a few examples:

Image Source: Professional medical MMLU question
Image Source: Professional medical MMLU question

Image Source: Professional accounting MMLU question
Image Source: Professional accounting MMLU question

Image Source: Professional legal MMLU question
Image Source: Professional legal MMLU question
Graduate and undergraduate students gathered MMLU’s questions from online resources. Though Hendrycks et al. did not specify any safeguards ensuring LLMs couldn’t train on these questions (beyond sharing sources that they selected their questions from), given the then-SOA models’ poor performance on MMLU (we’ll get to this in a bit), we can at least reasonably assume that those models didn’t memorize answers (though we can’t be so sure about current models).
Housed in this GitHub repo is MMLU’s trove of 15908 questions, testing qualitative (e.g., law, philosophy, and history) and quantitative analysis (e.g., physics, computer science, and mathematics), knowledge about human behavior and society (e.g., economics, sociology, politics, geography, and psychology), along with “empirical methods, fluid intelligence, and procedural knowledge.” An “other” category also exists for subjects that don’t fit neatly into the above buckets, including various statistics and facts, business, finance, accounting, marketing, and more. In total, MMLU contains at least 100 text examples for each of its 57 diverse subjects.
For scoring, MMLU averages each model’s performance per category (humanities, social science, STEM, and others) and then averages these four scores for a final score. To establish a human baseline, Hendrycks et al. asked non-specialist humans to answer MMLU questions. Their overall accuracy was only 34.5%, suggesting how challenging the professional-level, advanced knowledge questions are. Hendrycks et al. believe that individuals with specialized knowledge in one of the tested subjects would perform significantly better (but didn’t test this assumption).
After getting a human baseline, Hendrycks et al. tested numerous models on MMLU in few-shot and zero-shot settings, focusing their analysis on the two best-scoring models, GPT-3 (175 billion parameters) and UnifiedQA. Initial results from MMLU revealed intriguing insights. When MMLU was released, on average, the smaller LLMs tested tended to perform around chance (25% accurate), while the larger GPT-3 (175 billion parameters) fared better with 43.9% few-shot accuracy and 37.7% zero-shot accuracy. Below are the few-shot scores for the models initially tested on MMLU:
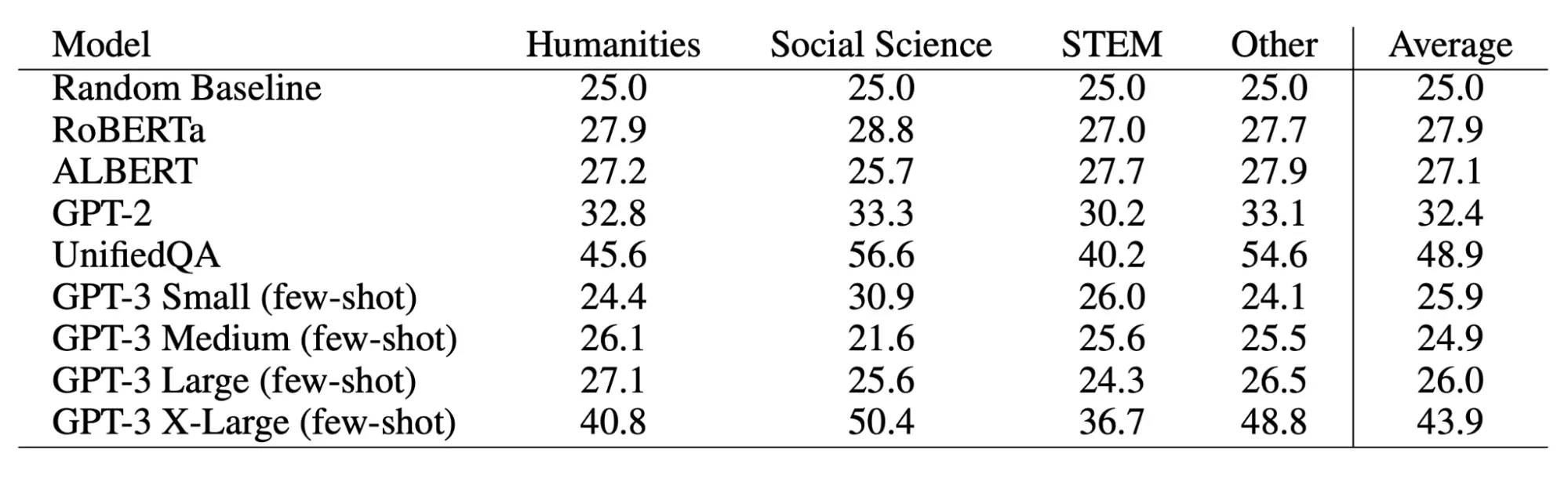
Image Source: Few-shot accuracy of initial models tested on MMLU
Image Source: Few-shot accuracy of initial models tested on MMLU
Interestingly, instead of excelling in a specific subject—the way we’d expect a highly specialized human professional to—GPT-3 showed lopsided performance across topics. Its best performance was 69% in a single subject (US foreign policy), and in its worst subjects (Chemistry at the bottom), GPT-3 barely scored above random chance guessing (25%). In general, the tested LLMs especially struggled at calculation-intensive tasks (e.g., physics and math) and in human-value-laden subjects (e.g., morality and law).
MMLU’s Contribution
Thankfully, LLMs have made significant progress on MMLU since its release (in 2020), but the benchmark remains challenging; the current open LLM Hugging Face leader for MMLU, Falcon-40B-Instruct, scores 54.1%, and the current closed model leader, GPT-4, scores 86.4%. Even if LLMs’ MMLU scores climb much higher, since it tests LLMs on a wide array of subjects, MMLU will remain helpful in revealing specific subjects where specific LLMs lag behind, charting a path for researchers to address weaknesses unique to their LLMs. MMLU also demonstrates that NLU is not monolithic; rather, it’s a composition of many smaller, often domain-specific tasks.
We’ve now learned about ARC, a question-answer benchmark; HellaSwag, a common sense benchmark; and MMLU, an NLU benchmark. In the final part of this series, we’ll explore TruthfulQA, a benchmark that, just as it sounds, gauges the truthfulness of LLM-generated responses.