Since the creation of GPT-3 in 2022, there has been a notable surge in the development of new large language models (LLMs). Corporations with substantial resources are now producing these models at an accelerated pace.
Often, these models are introduced alongside bold claims regarding their capabilities. While these LLMs may excel at natural language processing (NLP) tasks, they occasionally struggle with understanding instructions (context), exhibit hallucinations, or provide inaccurate outputs.
Researchers meticulously design evaluation tasks (benchmarks) to thoroughly assess these claims and challenge the current state-of-the-art (SOTA) LLMs. This rigorous testing aims to reveal their strengths and weaknesses, providing valuable insights for various stakeholders.
Understanding Large Language Models
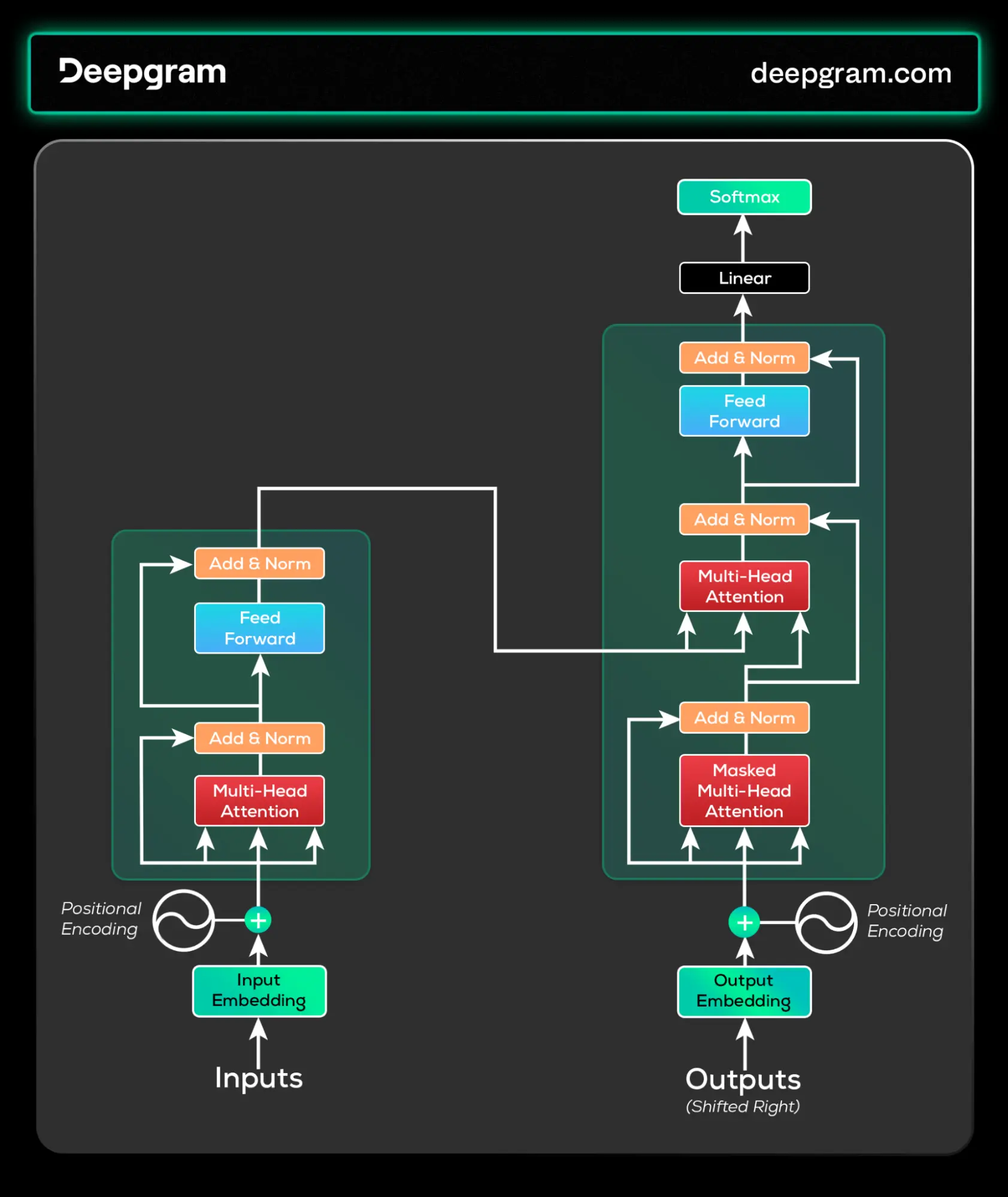
Large language models are mostly transformer-based deep learning models trained on large datasets. The transformer architecture introduces encoder and decoder components, each with self-attention mechanisms.
The encoder processes input data, capturing contextual information through self-attention, while the decoder generates output, utilizing self-attention for context awareness. With billions of parameters, these models can perform unsupervised learning and refine their capabilities through reinforcement learning based on human feedback. They mostly utilize this transformer model to perform their tasks because of its flexibility.
Here are a few players in the space and their LLMs that have been important to the field in the past few years:
BERT (Bidirectional Encoder Representations from Transformers): BERT is one of the most popular families of large language models and has created and marked a significant change in NLP research with its breakthrough bidirectional training.
It captures the context and nuances of language, setting a new standard for many NLP tasks. This model led to others like RoBERTa (Robustly optimized BERT approach) by Facebook AI Research and DistilBERT by Hugging Face.
PaLM (Pathways Language Model) and LaMDA (Language Model for Dialogue Applications): LaMDA is a conversational language model tailored for engaging in natural conversations across diverse topics. Trained on extensive dialog data, LaMDA aims to comprehend and generate human-like responses. Initially, Google's Bard utilized the LaMDA family of language models, but it later transitioned to a better model (PALM 2) due to benchmarked performance with other large models. It has up to 137B parameters and is pre-trained on 1.56T words of public dialog data and web text
In contrast to LaMDA, PaLM is seen as an improvement. Trained datasets span filtered webpages, books, news, Wikipedia articles, source code from GitHub, and social media conversations. It comprises 540 billion parameters, with smaller versions like 8 and 62 billion. In May 2023, Google announced PALM 2, which has 340 billion parameters trained on 3.6 trillion tokens. Currently, Google Bard uses it to assist you with NLP tasks like summarization, content generation, and translation, among others.
Open AI
GPT (Generative Pre-trained Transformers): The GPT family of large language models (GPT-1 to GPT-4) was created by OpenAI and emerged as a game-changer. These models have found widespread applications, from automated content creation to enhancing customer service experiences. The GPT series is famous for its wide range of language comprehension and generation capabilities, setting new benchmarks with each new version. From GPT-1 to 4, they have between 117 million parameters and 1 trillion to 170 trillion estimated parameters in the group of models, with GPT-4 having multimodal capabilities. It is one of the most used LLMs at the moment.
Cohere
Command-medium-nightly: Tailored for developers needing rapid responses in their applications, this model comes in two sizes: "command" and "command-light." While the "command" model boasts superior performance, "command-light" is the optimal choice for chatbot development. The nightly versions of these models undergo regular updates and are readily usable during active development by the Cohere team.
Anthropic
Claude family of models (Claude 1, 2 and Instant): This model is closely related to GPT-3 and 3.5 and was created for complex reasoning, creativity, coding, detailed content creation, and classification tasks. Claude 1 has 93 billion parameters, while Claude 2 has 137 billion. Their dataset was trained to avoid biases and ensure they only provided objective information. On the other hand, Claude Instant is the lighter of the two versions, with the capabilities of Claude Version 1.
Stanford University-LLaMA 7B model
Alpaca-7B: The Alpaca model is fine-tuned from the LLaMA 7B model. The creators say they behave similarly to OpenAI’s text-DaVinci-003 while being light, cheap, and easy to reproduce for under $600. It is worth mentioning that the Alpaca is open source and used for research purposes. Data used to fine-tune the LLaMA 7B came from the text-davinci-003.
Other key players and products are out there, like Bloom from Hugging Face, Vicuna 33B, Falcon, etc. Although they are all great LLMs, they are known to perpetuate some level of bias, toxicity, and hallucinations, but with more benchmarks and improvements, these LLMs will become better at performing their tasks without these issues.
Importance of Benchmarking in Evaluating and Comparing LLM Performance
Benchmarking is crucial for shaping the development of Large Language Models (LLMs), guiding innovation and refinement. In machine learning, benchmarking involves assessing models through standard tests, datasets, and criteria. It acts as a diagnostic tool, offering insights into model capabilities and limitations, like a GPS network providing a clear view of a model's position in the AI landscape.
They all accomplish different goals and they are important for the following reasons:
It provides a common ground for comparing different models, aiding in understanding the strengths and weaknesses of each approach.
It helps organizations allocate resources effectively by identifying which models excel in specific tasks and guiding company or research directions.
It contributes to standardizing evaluation metrics and practices, fostering collaboration and communication within the ML community.
Benchmarks can include evaluations of bias, fairness, and ethical implications, guiding the development of more responsible AI.
Benchmarks with defined metrics and datasets ensure reproducibility in experiments, a crucial aspect of scientific research.
It allows tracking progress over time, showcasing improvements in new LLMs compared to previous versions.
Developers rely on benchmarks to choose the most suitable model for specific applications, impacting the performance and reliability of ML-driven products.
As models like GPT-3 and BERT transform language processing, thorough benchmarking will gain significance. Various benchmarks assess different language aspects, from natural language inference to translation quality.
In essence, benchmarking LLMs is not just a measure of performance; it's a compass guiding progress that leads to innovation and ensures responsible advancements in artificial intelligence.
Challenges in Benchmarking
Benchmarking Large Language Models (LLMs) present a unique set of challenges for the following reasons:
Benchmarking is challenging due to measuring nuanced comprehension beyond literal text understanding. LLMs tackle diverse comprehension tasks, including context, sentiment, and humor, mirroring human communication intricacies.
Benchmarking is complex as it demands versatility across a broad spectrum for a comprehensive performance evaluation. LLMs may excel in legal jargon but face challenges with colloquial speech or creative writing, requiring them to generalize across diverse domains.
The training datasets for these models have an inherent bias in them. So if the benchmarking isn’t done well by not considering bias and fairness but only performance, it may perpetuate biases in the data.
Creating a unified benchmark for all NLP tasks is challenging, particularly because the diverse nature of tasks introduces complexity, making benchmarking both challenging and less reproducible.
Current emphasis is placed on leaderboard performances based on select benchmarks. Instead of viewing benchmarking as a competition, organizations and researchers should see it as a tool to compare and enhance models, addressing both performance and fairness requirements
Key Metrics for Benchmarking
Benchmarking metrics are the litmus test for assessing the capabilities of these advanced AI systems. Among the many metrics available, a few stand out for their critical role in capturing different performance dimensions.
Accuracy: This is the most direct metric, representing the proportion of predictions a model gets right. It's applied across various tasks, from classification to question answering, providing a straightforward assessment of a model's performance.
Perplexity: It measures a model's language prediction abilities. Lower perplexity indicates a model is better at predicting the next word in a sequence, suggesting a higher level of language understanding. This metric is particularly telling in tasks like text completion or language modeling.
F1 score (precision and recall): The F1 Score combines precision and recall into a single metric, balancing not missing relevant instances (recall) and ensuring correct predictions (precision). It's vital for tasks where the balance between these factors is crucial, such as information retrieval.
BLEU Score (Bilingual Evaluation Understudy): It is tailored for translation tasks. It measures how closely a model's translation matches a set of high-quality reference translations, grading the fluency and accuracy of the translated text.
Other metrics worth mentioning are ROGUE (Recall-Oriented Understanding for Gisting Evaluation) for evaluating text summarization tasks and the EM (Exact Match) score for question answering. All these metrics reveal different aspects of LLM performance.
Perplexity gauges linguistic intuition, accuracy measures correctness, the F1 score evaluates the trade-off between comprehensive retrieval and precision, and the BLEU score assesses cross-lingual understanding.
Together, they provide a comprehensive picture of an LLM's abilities, ensuring models are not just statistically powerful but also practically proficient in handling the complexities of human language.
Existing Benchmarks for ML Tasks
Evaluating LLMs in NLP and Natural Language Understanding (NLU) tasks is crucial in determining their effectiveness and applicability. Several benchmarks have emerged as industry standards, each with its own focus and challenges. Let's explore some of the prominent benchmarks: GLUE, SuperGLUE, HellaSwag, ARC, and MMLU
GLUE (General Language Understanding Evaluation): GLUE is a collection of nine NLP tasks, including sentiment analysis, textual entailment, and linguistic acceptability. It is designed to assess the ability of models to understand text. The strength of GLUE lies in its comprehensive approach, which covers a wide range of linguistic phenomena. However, as models began to surpass human performance on GLUE, its ability to differentiate between more advanced LLMs diminished.
SuperGLUE (Super General Language Understanding): Developed as a more challenging successor to GLUE, SuperGLUE consists of tasks that require deeper linguistic and logical understanding, such as question answering and coreference resolution. The strength of SuperGLUE is its complexity, which challenges even the most sophisticated LLMs. Its limitation, however, is that it can encourage overfitting, where models are excessively fine-tuned to their specific tasks.
HellaSwag (Harder Endings, Longer Contexts, and Low-shot Activities for Situations with Adversarial Generations): This benchmark tests a model's common-sense reasoning and prediction abilities, requiring it to complete realistic scenarios. HellaSwag pushes LLMs to understand and anticipate real-world situations, a vital aspect of NLU. Its limitation lies in its focus on a specific type of reasoning, which may not comprehensively gauge a model's overall language understanding.
ARC (AI2 Reasoning Challenge): ARC focuses on grade-school-level multiple-choice science questions. It tests a model's reasoning and understanding in a knowledge-intensive domain. ARC's strength is evaluating a model's ability to integrate language understanding with factual knowledge. However, its specialized nature may not reflect a model's performance on broader linguistic tasks.
MMLU (Massive Multitask Language Understanding): A recent addition, MMLU assesses models across 57 tasks covering a range of subjects and languages. It is designed to test both the depth and breadth of understanding. The strength of MMLU lies in its diversity and scale, making it a resource-intensive benchmark.
These benchmarks focus on specific aspects of language understanding, which can lead to models being optimized for test conditions rather than real-world applicability. There's also a risk of overfitting benchmark datasets. As LLMs evolve, so must the benchmarks. This will continue to make them challenging and relevant to accurately reflecting human language's diverse and nuanced nature.
Future Direction of LLM Benchmarking
As we look ahead, LLMs will become more important as they better comprehend human language and contexts. This means that benchmarks must keep up with the quick changes and provide adequate tests to provide a good idea of both performance on different testing scales.
Models like GPT-4 and Google’s Gemini are getting better at grasping the subtleties of human conversations, so the tests will need to be more advanced too. They should move beyond just using fixed datasets and work to simulate real-world situations.
Another challenge will be dealing with the size of these models. As they get increasingly complex, the tests need considerable computer power, which may make it harder for researchers and developers to use them.
Also, since these models are getting more involved in everyday applications, the tests should not just look at how well they work technically but also if they're doing things fairly and ethically. This means ensuring the models don't favor certain groups and respect people's privacy. It's a big task for the people making the tests.